AI-driven crawlers skim and summarise website content, redirecting readers to only a few of the original sources. This shift has led to fewer visits, lower ad revenue, and growing concern among publishers.
Cloudflare has come to the rescue by providing publishers with options ranging from entirely to partially blocking AI crawler bots, as well as charging crawler bots for access to content. These changes could put publishers back in the driving seat while still allowing helpful bots to index and display essential information.
The web’s traffic trade is shifting
Almost three decades ago, search engines linked users to publisher sites in exchange for displaying content snippets. That simple pact drove ad views, subscriptions, and the thrill of audience reach.
Over time, Google has built an entire search ecosystem:
- Chrome browsers for using Google as the default search engine.
- Heavily experimented on SERP page features.
- Acquired DoubleClick to launch AdSense to give publishers a way to monetise their content.
- Launched Google Webmaster Tools, which is now known as Google Search Console.
- And acquired Urchin to offer Google Analytics for people to analyse their traffic.
Now, AI crawlers scan and summarise entire pages, rarely sending readers back to the original sources. Search still sends some traffic, but AI/LLMs are tipping the balance.
Six months ago, the ratios looked like this:
Google: 3.7:1
OpenAI: 1300:1
Anthropic: 356,000:1
And still today, that picture isn’t any better:
Google: 6.1:1
OpenAI: 1200:1
Anthropic: 39,100:1
This shift shows AI reads and answers with a few referrals, leaving publishers with less traffic and fewer opportunities to monetise their work.
How Cloudflare is giving publishers control back
Cloudflare’s new Pay-Per-Crawl model is built on choice: publishers decide who can crawl their site and under what terms. Whether you want to block or allow AI crawlers completely or open your content to AI platforms that pay for access, the control is yours. This section breaks down two key features of Cloudflare that put publishers in the driver’s seat.
The default opt-out of AI crawlers
Cloudflare addressed publishers’ concerns by launching a one-click setting to block all AI crawlers last year. But managing that option manually proved too much work for busy teams.
Now, any new site on Cloudflare automatically opts out of AI crawling by default. No action required. If you choose to allow or unblock AI crawlers’ access later, simply:
- Go to your Cloudflare dashboard
- Navigate to the Overview page
- Find the ‘Block AI Training Bots’ section
- Select ‘Do not block (off)’ from the drop-down
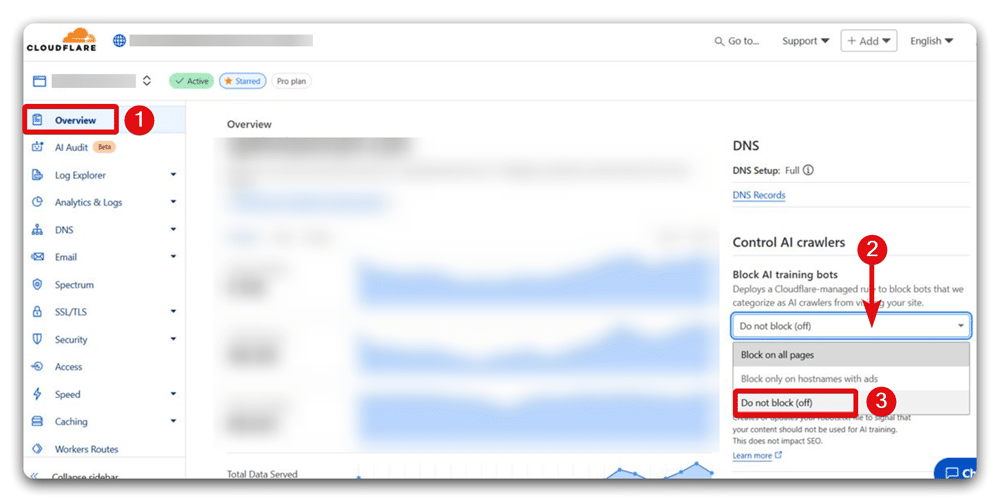
This approach ensures every publisher starts with protection, yet can grant permissions quickly when ready.
Pay Per Crawl: Charge crawlers on a per-request basis
Cloudflare has introduced a private beta program called Pay Per Crawl, which aims to provide a third option for its users to move beyond blocking or free access to AI crawlers. Publishers can now charge crawlers for each request. Here’s the flow:
- A crawler requests content. The server responds with HTTP 402 Payment Required and price details.
- If the crawler pays via a follow-up request with a payment header, the server returns the content with a 200 OK status.
- If no payment arrives, access is denied.
While publishers can set a flat price across their entire site, they also have the option to allow specific crawlers free access or negotiate separate agreements for individual sites. Cloudflare enforces these Allow or Charge decisions using a rules engine that runs after existing WAF policies and bot management settings.
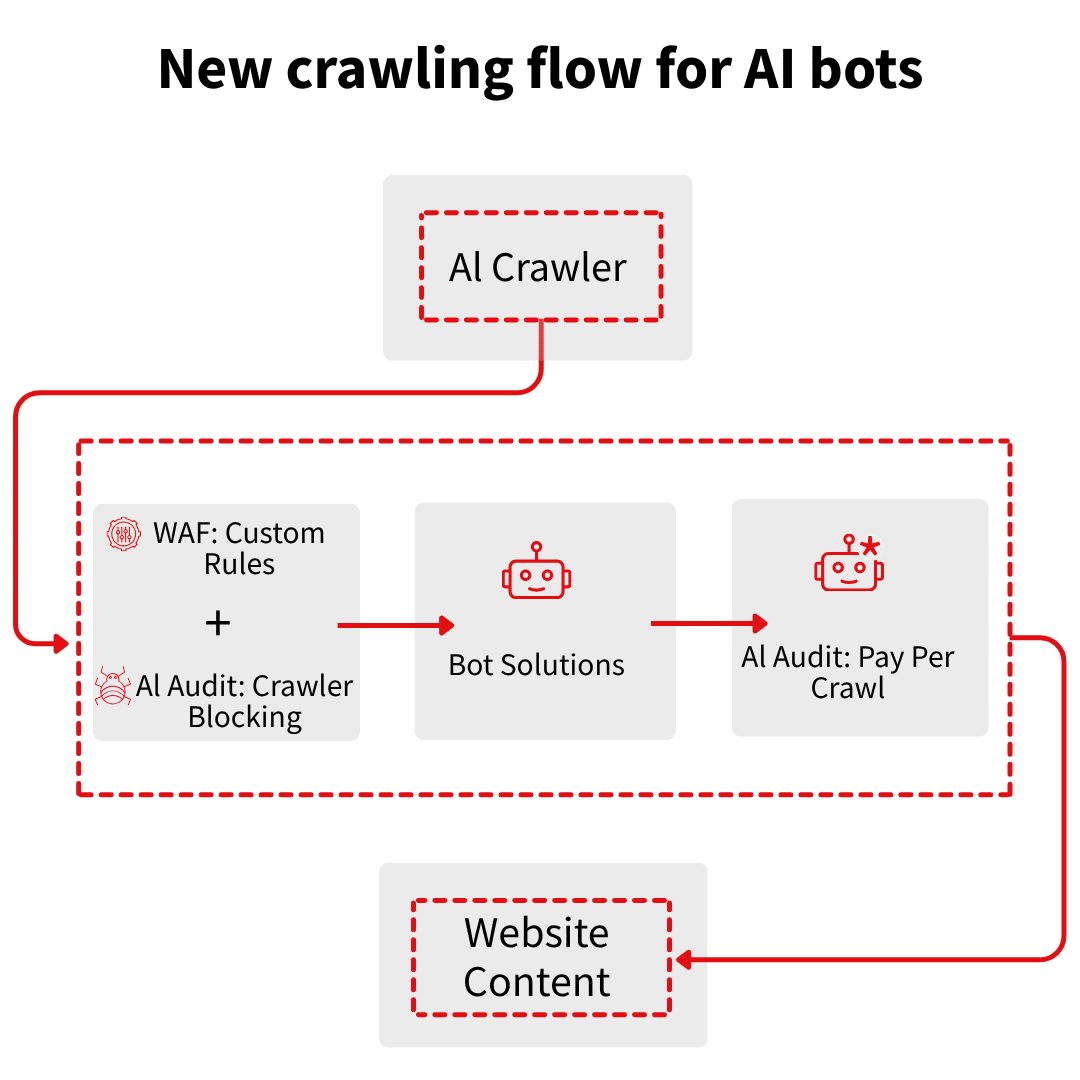
In the Cloudflare dashboard, you can choose one of three rules for each crawler:
- Allow: Grant free access to the content (HTTP 200).
- Charge: Require payment per request for accessing website content (HTTP 402 with price information).
- Block: Deny access to website content (HTTP 403)
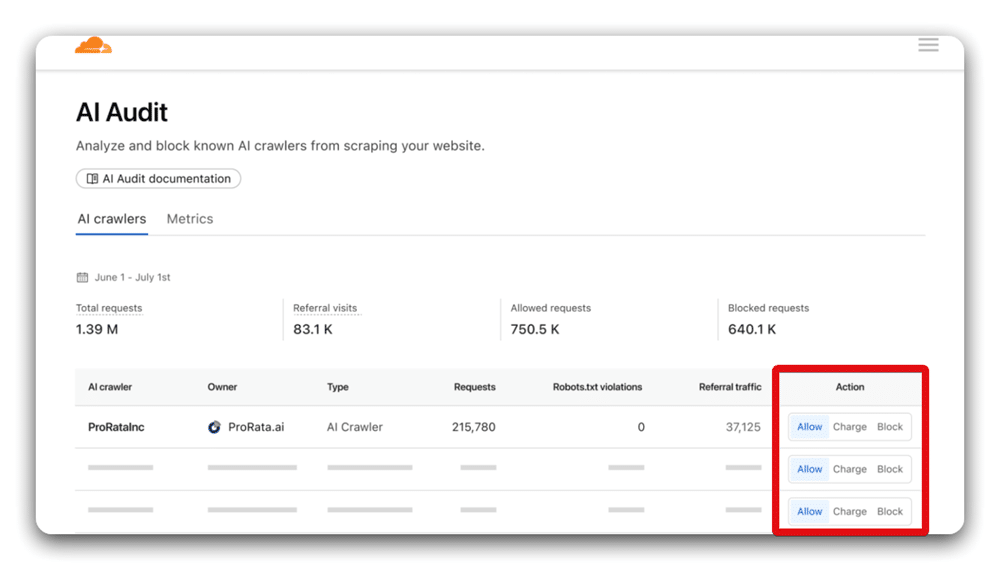
Source: Cloudflare
This system treats content as a paid service for crawlers, providing publishers with a way to earn revenue from AI bots’ crawling.
Should you use Clouflare’s pay-per-crawl feature?
Blocking or charging AI crawlers will likely reduce overall traffic to your site. And from the AI referral traffic that we have tracked in Google Analytics, we can see that this is often highly engaged traffic.
It’s also important to remember that AI/LLM crawlers are probably only going to be willing to pay to crawl very reputable sites with lots of original content being produced regularly. If you don’t fall into that bracket, they’re unlikely to pay.
This is very good for reputable publishers who have had their traffic decimated because of AI/LLMs. As they can get their money back from lost traffic by charging LLMs to crawl their original content.
Larger, high-traffic publishers will have much more leverage when negotiating prices. If you own a smaller, niche site, you risk being ignored by crawlers altogether and losing even more visibility.
How much should you charge per crawl?
This is a very interesting question. And I’m curious to see how big websites like Forbes and LLMs like Gemini negotiate this. You need to understand how much each user is worth that is being lost to LLM searches. This is quite difficult because there isn’t great visibility on the number and context of searches made on LLMs, as they’re often complex searches.
Understanding the number of times your website is cited by LLMs could be a key factor, and there are SEO tools out there starting to understand this better.
Negotiating prices will become simpler when marketers understand how to measure AI/LLM search better.
Is the pay-per-crawl feature a good thing?
Compensation for creators is definitely important. Otherwise, businesses can’t afford to create. This is putting some power back into the hands of site owners.
However, this creates a fragmented ecosystem where only rich, well-established publishers charge and get paid. Whereas smaller creators have to give content away just to stay visible.
What do you think?